
Dernièrement, il y a eu beaucoup de discussions parmi les initiés et ceux qui suivent de près l’histoire du « vaccin à ARNm » contre la COVID concernant la contamination des vaccins à ARNm par des fragments d’ADN qui incluent des séquences d’ADN dérivées du virus simien 40 (SV40).
Est-ce juste un autre intérieur du baseball tempête dans une théière, semblable aux diverses conspirations marginales promues par les « experts/théoriciens des médias sociaux », aux controverses amplifiées par la peur du porno concernant l'oxyde de graphène, les hydres vivantes ou le venin de serpent dans les vaccins, ou que les nanoparticules lipidiques-pseudoARN sont en réalité Nanobots de science-fiction Star-Trek du 24e siècle qui va reprogrammer tous nos cerveaux ?
Cette question de contamination/falsification de l’ADN est-elle réelle et devrait-elle réellement vous préoccuper – ainsi que les tribunaux ?
Drs. David Speicher, Kevin McKernan et leurs collègues sont en réalité de véritables experts scientifiques et techniques sérieux dans l'application concrète de la méthodologie d'analyse biologique séquentielle et moléculaire. C’est ce qu’ils font, jour après jour, pour gagner leur vie. Il s’agit du domaine technique spécifique sur lequel ils font rapport.
Ce ne sont pas des marginaux »marais de fièvre» les théoriciens du complot (terme de Steve Bannon).
Dr David J. Speicher, Département de pathobiologie de l'Université de Guelph, 50 Stone Rd E, Guelph, ON, N1G 2W1, speicher@uoguelph.ca , ORCID0000-0002-1745-3263
Ce que Speicher et al observent et rapportent dans ce manuscrit scientifique lien ci-dessous démontre clairement un échec profond de la FDA et des autorités réglementaires mondiales à accomplir leur travail le plus important : garantir la pureté et l’absence de falsification des produits pharmaceutiques dont ils autorisent la commercialisation et l’utilisation par les médecins et les professionnels paramédicaux.
Au minimum, cela démontre une fois de plus l’aveuglement volontaire généralisé qui semble avoir envahi la branche des vaccins de la FDA/CBER sous la direction des « vrais croyants » du Dr Peter Marks, qui n’est ni un expert en vaccins, ni un immunologiste, ni un expert en biologie moléculaire. biologiste, ni quelqu'un qui a une quelconque compréhension de l'administration de polynucléotides à base de nanoparticules lipidiques non virales, mais qui est plutôt un hématologue/oncologue clinicien qui est à l’origine de l’approche « opération warp speed » et qui continue de promouvoir le développement d’un vaccin (et maintenant d’un médicament contre le cancer). C’est-à-dire en contournant presque toutes les procédures normales et les leçons tirées de décennies de développement, de fabrication, d’approbation de commercialisation et de surveillance post-commercialisation de produits biologiques et médicamenteux.
Pire encore, avec ces nouvelles informations, on voit apparaître une « preuve irréfutable » démontrant une collusion corrompue entre les autorités de réglementation pharmaceutique des États-Unis et d'autres États administratifs occidentaux et l'industrie pharmaceutique.
D’après mon évaluation personnelle de ces données, cette contamination semble répondre aux critères formels de « falsification » pharmaceutique, qui est strictement interdite par la loi fédérale américaine. La prévention de la « falsification » des médicaments, des appareils et des aliments est l’une des missions centrales de la FDA – essentiellement, l’une des principales raisons pour lesquelles la FDA a été créée en premier lieu.
Une question clé qui reste en suspens est de savoir comment cela est-il arrivé ?
Cette falsification était-elle connue de la FDA, de l'EMA, du Institut Paul Ehrlich, Santé Canada etc. et caché du public ? Si on ne le sait pas, comment cette falsification a-t-elle pu échapper à la détection par pratiquement tous les experts gouvernementaux autorisés en matière de réglementation des pays occidentaux ?
Ci-dessous, une capture d'écran du tweet avec un lien au manuscrit pré-imprimé associé qui a déclenché cette dernière tempête de feu.

Abstract
Contexte: Les réactions de transcription in vitro (IVT) utilisées pour générer de l'ARN modifié par nucléosides (modRNA) pour les vaccins contre le SRAS-CoV-2 reposent actuellement sur une transcription d'ARN polymérase à partir d'une matrice d'ADN. La production du modRNA utilisé dans l’essai clinique randomisé (ECR) original de Pfizer utilisait une matrice d’ADN générée par PCR (processus 1). Pour générer des milliards de doses de vaccin, cet ADN a été cloné dans un vecteur plasmidique bactérien pour amplification dans Escherichia coli avant linéarisation (processus 2), augmentant ainsi la taille et la complexité de l'ADN résiduel potentiel et introduisant des séquences non présentes dans la matrice du processus 1. Il semble que Moderna ait utilisé un processus similaire basé sur les plasmides pour les vaccins utilisés lors des essais cliniques et après les essais. Récemment, des études de séquençage de l’ADN ont révélé cet ADN plasmidique à des niveaux significatifs dans les vaccins modRNA Pfizer-BioNTech et Moderna. Ces études ont porté sur un nombre limité de lots et des questions demeurent quant à la variance de l'ADN résiduel observée à l'échelle internationale.
Méthodologie: À l'aide de séquences d'amorces et de sondes publiées précédemment, une réaction en chaîne par polymérase quantitative (qPCR) et une fluorométrie Qubit® ont été réalisées sur 27 flacons d'ARNm supplémentaires obtenus au Canada et tirés de 12 lots uniques (5 lots de Moderna monovalent enfant/adulte, 1 lot de Moderna adulte bivalent BA.4/5, 1 lot de Moderna bivalent enfant/adulte BA.1, 1 lot de Moderna XBB.1.5 monovalent, 3 lots de Pfizer adulte monovalent et 1 lot de Pfizer adulte bivalent BA.4/5). La base de données du Vaccine Adverse Events Reporting System (VAERS) a été interrogée pour connaître le nombre et la catégorisation des événements indésirables (EI) signalés pour chacun des lots testés. Le contenu d’un flacon du vaccin Pfizer COVID-19 précédemment étudié a été examiné par séquençage Oxford Nanopore pour déterminer la distribution de taille des fragments d’ADN. Cet échantillon a également été utilisé pour déterminer si l'ADN résiduel est encapsulé dans les nanoparticules lipidiques (LNP) et donc résistant à la DNaseI ou si l'ADN réside à l'extérieur du LNP et est labile à la DNaseI.
Résultats: Les valeurs du cycle de quantification (Cq) (dilution 1:10) pour l’origine plasmidique de réplication (ori) et les séquences de pointes variaient respectivement de 18.44 à 24.87 et de 18.03 à 23.83 pour Pfizer, et de 22.52 à 24.53 et de 25.24 à 30.10 pour Moderna. Ces valeurs correspondent à 0.28 – 4.27 ng/dose et 0.22 – 2.43 ng/dose (Pfizer), et 0.01 – 0.34 ng/dose et 0.25 – 0.78 ng/dose (Moderna), pour ori et Spike respectivement mesurés par qPCR, et 1,896 3,720 – 3,270 5,100 ng/dose et 40 16.64 – 22.59 214 ng/dose mesurés par fluorométrie Qubit® pour Pfizer et Moderna, respectivement. Le promoteur-enhancer-ori SV3.5 n’a été détecté que dans les flacons Pfizer avec des scores Cq allant de XNUMX à XNUMX. Dans une analyse exploratoire, nous avons trouvé des preuves préliminaires d'une relation dose-réponse entre la quantité d'ADN par dose et la fréquence des événements indésirables graves (EIG). Cette relation était différente pour les produits Pfizer et Moderna. L'analyse de la distribution de taille a révélé des longueurs moyennes et maximales de fragments d'ADN de XNUMX paires de bases (pb) et XNUMX kb, respectivement. L'ADN plasmidique se trouve probablement à l'intérieur des LNP et est protégé des nucléases.
Conclusion: Ces données démontrent la présence de milliards, voire de centaines de milliards de molécules d’ADN par dose dans ces vaccins. Grâce à la fluorométrie, tous les vaccins dépassent de 10 à 188 fois les directives relatives à l'ADN résiduel fixées par la FDA et l'OMS de 509 ng/dose.. Cependant, la teneur en ADN résiduel de la qPCR dans tous les vaccins était inférieure à ces lignes directrices, ce qui souligne l'importance de la clarté et de la cohérence méthodologiques lors de l'interprétation des lignes directrices quantitatives. Les preuves préliminaires d’un effet dose-réponse de l’ADN résiduel mesuré par qPCR et SAE justifient une confirmation et une enquête plus approfondie. Nos résultats élargissent les préoccupations existantes concernant la sécurité des vaccins et remettent en question la pertinence des lignes directrices conçues avant l’introduction d’une transfection efficace à l’aide des LNP. Avec plusieurs limites évidentes, nous insistons pour que nos travaux soient reproduits dans des conditions médico-légales et que les lignes directrices soient révisées pour tenir compte d'une transfection d'ADN et d'un dosage cumulatif très efficaces.
Vous pouvez consulter vous-même le manuscrit complet en suivant ce lien.
Comprendre la science derrière cette découverte.
Pour suivre les aspects techniques et la signification de ce qui a été découvert et démontré, vous devez comprendre quelques bases de biologie moléculaire. Je ferai de mon mieux pour expliquer et fournir le contexte nécessaire à ceux qui n'ont pas suivi de formation universitaire en biologie moléculaire de division supérieure. J'avoue être un peu trop proche du sujet, et parfois j'assume trop de connaissances de base. Si c'est le cas, c'est ma faute. Comme Le professeur Richard Feynman est crédité d'avoir dit, "Si vous ne pouvez pas expliquer quelque chose en termes simples, vous ne le comprenez pas." Je vais essayer d'être à la hauteur de ses standards.
Il faut commencer par le « dogme central » de la biologie. L'ADN fabrique l'ARN, l'ARN fabrique les protéines.
Si vous souhaitez fabriquer de grandes quantités d'ARN pur, vous devez essentiellement commencer avec de grandes quantités d'ADN et utiliser une enzyme protéique (bactériophage). ARN polymérase T7 dans ma méthode originale, qui est toujours utilisé), ainsi que des sous-unités chimiques d'ARN et une source d'énergie (ATP) pour fabriquer l'ARN à partir de l'ADN. Ensuite, vous devez décomposer l’ADN en petits fragments tout en laissant intact le plus gros ARN. Ensuite, vous devez purifier les petits fragments d’ADN des plus gros ARN. Dans mon procédé initial, cela se faisait à l'aide d'une sorte de filtre (chromatographie sur gel) qui laisse passer les fragments d'ADN peu dégradés et les petites sous-unités chimiques inutilisées plus rapidement que les grosses molécules d'ARN. Et puis vous jetez ce qui sort en premier – les petits trucs (fragments d’ADN et produits chimiques inutilisés) et conservez les gros trucs qui ressortent plus tard – qui sont essentiellement de l’ARN pur dissous dans l’eau.
Cela a-t-il du sens?
Ensuite, une fois que vous avez cet ARN purifié chargé négativement dans l'eau, vous pouvez le rendre plus ou moins concentré, le mélanger de manière sophistiquée avec d'autres éléments comme des graisses chargées positivement qui s'auto-assemblent pour produire des nanoparticules lipidiques, le stocker dans un flacon en verre et l'injecter aux gens. Et c’est en un mot le processus de fabrication des vaccins pseudo-ARNm.
Qu’est-ce qui pourrait mal se passer, demandez-vous ?
Dans ce cas, au moins deux choses semblent avoir mal tourné. Le premier concerne l’ADN utilisé pour fabriquer l’ARN . Et la seconde concerne le processus de dégradation et de purification de l’ADN utilisé.aussi comme discuté ci-dessus>.
Apparemment, deux manières différentes ont été utilisées pour fabriquer l’ADN. Le processus de fabrication original utilisé pour les essais cliniques initiaux utilisait la réaction en chaîne par polymérase, qui peut être et a été utilisée pour fabriquer des fragments linéaires d'ADN plus grands (la précision est quelque peu problématique), qui ont ensuite été utilisés pour produire l'ARN. Cela s’est avéré trop difficile, trop coûteux, trop long, etc. pour soutenir une fabrication de masse au niveau nécessaire pour prendre en charge le dosage mondial. Apparemment, Pfizer/BioNTech et Moderna sont tous deux revenus à la méthode originale que j'ai utilisée, qui reposait sur un ADN « plasmidique » circulaire produit à l'aide de bactéries (souches spéciales de laboratoire de bactéries). E. coli, quelle bactérie se trouve couramment dans votre intestin).
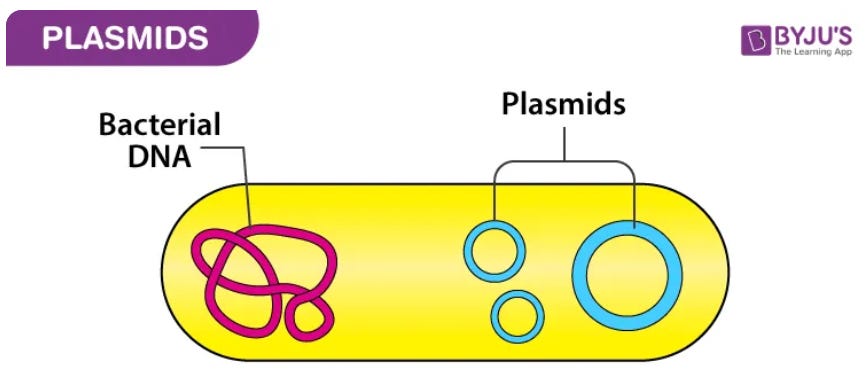
Vous pouvez considérer les plasmides comme les formes les plus pures d’un virus bactérien. Il existe d'autres éléments plus viraux qui infectent les bactéries (appelés bactériophages), mais les plasmides sont des ADN circulaires qui peuvent littéralement infecter les bactéries sous forme d'ADN pur et peuvent diriger ces bactéries pour qu'elles se transfèrent elles-mêmes ainsi que d'autres plasmides d'une bactérie à une autre.
Ces plasmides sont comme de petits cercles d'ADN parasite qui peuvent souvent aider l'hôte bactérien à mieux survivre dans certaines conditions telles que l'exposition à des antibiotiques, et sous ces pressions de sélection, les plasmides sont maintenus par les bactéries car ils offrent un avantage en matière de survie ou de reproduction. Si le plasmide ne fournit pas d'avantage, d'autres bactéries similaires supplanteront celles qui possèdent le plasmide, car le maintien du plasmide parasitaire a un coût pour l'hôte bactérien. .
Si vous souhaitez cultiver et récupérer (ergo fabriquer) le plus d'ADN plasmidique possible dans une culture de E. coli bactéries, vous souhaitez utiliser le plasmide le plus petit et le plus épuré qui puisse être conçu. Parce que toute séquence d’ADN supplémentaire dans le plasmide entraînera une production moindre de plasmide par litre dans la culture bactérienne résultante. Par conséquent, vous ne souhaitez pas ajouter dans ce plasmide des séquences d'ADN dont vous n'avez pas besoin pour la réplication du plasmide, la sélection des antibiotiques (la kanamycine ou la néomycine dans ce cas) et la fabrication éventuelle de l'ARN. Est-ce que cette partie a du sens pour vous ?
Alors pourquoi, au nom du ciel, une entreprise développant et déployant un processus de fabrication basé sur un plasmide pour la synthèse à grande échelle d’ARN à partir d’une matrice d’ADN inclurait-elle des séquences dans le plasmide qui ne sont pas nécessaires aux fins prévues ? Pourquoi ajouter des séquences extraites d’un virus à ADN oncogène connu (c’est-à-dire cancérigène) comme le virus simien 40 (SV40) ?
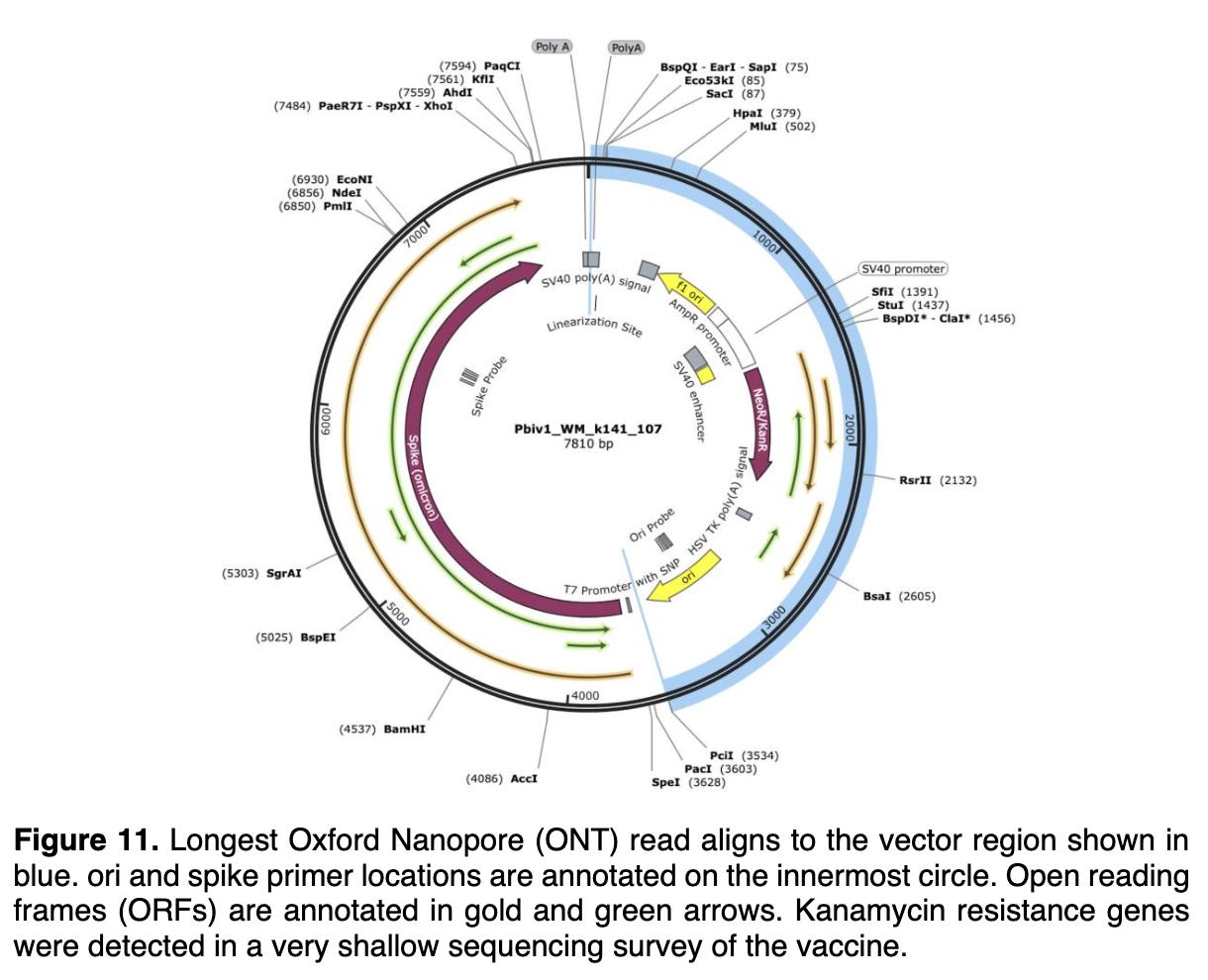
Il s’avère que ces séquences spécifiques du SV40 qui ont été identifiées dans la contamination des fragments d’ADN plasmidique documentée (ci-dessus) par Speicher et al sont couramment utilisées dans un type spécifique de plasmide bactérien modifié qui a été développé il y a des décennies pour être utilisé par les biologistes moléculaires. Il s’agit d’une technologie d’ADN recombinant de « noyau commun » bien établie.
Les plasmides bactériens peuvent être conçus et ont depuis longtemps été conçus pour se répliquer et produire de l'ARN (et des protéines) dans les bactéries et dans les cellules animales. De tels plasmides sont appelés « vecteurs navettes » dans l’industrie. Ils peuvent être fabriqués et purifiés en grande quantité en laboratoire. E. coli souches, puis transférées (« transfectées ») dans des cellules animales où elles peuvent se répliquer pendant un certain temps (sous certaines conditions) et produire l'ARN et la protéine d'intérêt dans les cellules animales – sous le contrôle de séquences dérivées du SV-40. dans ce cas.
Alors, que diable font les séquences SV-40 dans des plasmides dont le seul but est d’être purifiées et utilisées pour produire de grandes quantités d’ARN « dans le tube à essai » en utilisant un processus de fabrication à base d’enzymes de qualité commerciale ? Bonne question.
Je peux spéculer ou émettre des hypothèses, mais je suggère que c'est le travail de M. Pharma et de M. Government Regulator de répondre à cette question. Et pourquoi cela n'a jamais été divulgué au public, et encore moins soumis à une évaluation formelle des risques possibles lorsque de petits fragments de ces SV-40 et d'autres séquences d'ADN plasmidique (y compris des fragments de gènes de résistance aux antibiotiques) sont introduits dans le corps de patients utilisant la technologie d'administration systémique in vivo non virale la plus efficace jamais développée dans l'histoire du monde.
Puis-je imaginer des risques possibles ?
Bref, oui. D’une manière ou d’une autre, ces fragments sont susceptibles d’avoir au minimum un impact sur l’expression des gènes dans les cellules humaines qui absorbent l’ADN. Un possible l’impact pourrait impliquer le développement de cancers – ce que les biologistes moléculaires et les chercheurs en cancérologie appelleraient transformation (notez l'accentuation). Ces risques auraient-ils dû être étudiés avant que tout cela puisse se dérouler et être injecté à des êtres humains (à leur insu) ? Bien sûr, ils auraient dû. Et il va de soi que tout cela aurait dû être divulgué à toutes les personnes concernées. Si la FDA, l'EMA, Institut Paul Ehrlich, Santé Canada etc. n'étaient pas informés, il s'agirait alors d'une fraude. Si ils ont étéinformé et n'a rien fait, cela constituerait une négligence criminelleà mon avis, mais je suis médecin, pas JD>.
Cependant, il existe une mise en garde importante concernant les séquences SV40 dans les plasmides Pfizer/BioNTech et Moderna qui est rarement, voire jamais mentionnée dans les discussions actuelles, à savoir que le principal mécanisme par lequel le SV40 entraîne le développement de tumeurs solides (sarcomes) est le « Protéine « Large T Antigen » produite par le virus. Les séquences d'ADN de cette protéine ne sont présentes dans aucun de ces plasmides.
Je prédis un ouragan de propagande de vérification des faits, d’obscurcissements et de whaddaboutisme à propos de tout cela, mais les faits fondamentaux sont incontestables.
Quote partir Sous-empilement
Publié sous un Licence internationale Creative Commons Attribution 4.0
Pour les réimpressions, veuillez rétablir le lien canonique vers l'original Institut Brownstone Article et auteur.








